10 用广度优先搜索去开锁(第3/3页)
让我们想象一下广度优先搜索算法是怎么搜索一个图的。一个图是一种由点和边组成的数据结构。如果两个点由一条边相连,我们就可以说这两个点是相邻的。在警用算法课上你已经见识到了一个图:Kingdom HighwayMap。这个图里的每个点代表一个城市,而每条边则代表一条连接两个城市的高速公路。罪犯们一般都倾向于逃离他们所在城市,而你则需要找出他们最可能逃到哪些相邻的城市。
搜索Kingdom HighwayMap是一个经典的图上搜索问题。我们搜索的状态是图上的点,也就是地图上的城市。假设现在有人在A城市犯了罪,而你的目标是找到罪犯在哪。
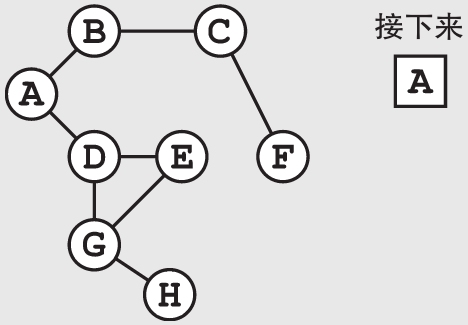
广度优先搜索会沿着一个不断延伸的边界展开。这个算法会先检查所有离起点X步的点,然后才会继续检查离起点X+1步的点。当你检查完A城市后,它的两个相邻城市B和D会被加到队列的最后。此时的队列中没有别的城市了,所以接下来算法会检查B城市。
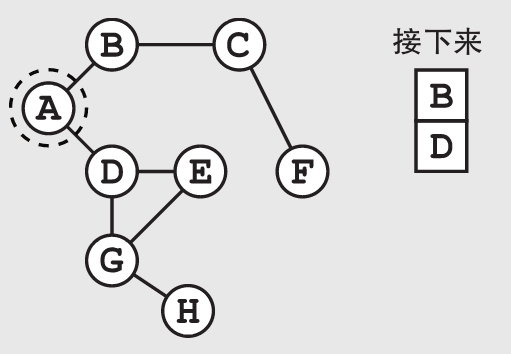
如果每个点都有很多相邻的点的话,维护这个队列就会占用大量的内存空间。在搜索一个大规模的问题时,这个内存需求会变得相当巨大。这时,作为警官的你就会打算多买一些质量好的笔记本。
在广度优先搜索的每一步,我们都需要先看看当前的点是不是我们的最终目标。在这个具体的例子当中,我们需要把当前点对应的城市仔细搜查一遍,看看罪犯是不是藏在这个城市中。如果当前的点还不是我们想找的目标,就把与它相邻的点中还未被检查过的点(也就是我们之前从来没有加到列表中的点)加到列表中。如此一来,我们可以避免重复添加已经检查过的点,以及虽然还未检查过但已经在列表里的点。在这个具体的例子中,检查过城市B后,我们将不会重复添加城市A(虽然它和B城市是相邻的,但我们已经检查过它了)。
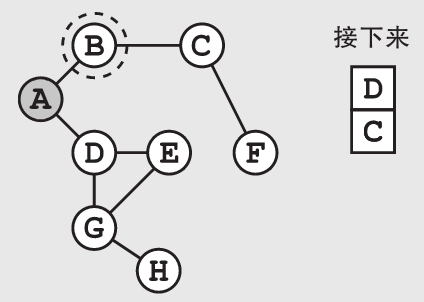
请注意,如果我们想要检查一个点在之前是否已经被添加过,将需要更多的内存,因为我们需要记录下所有已经被加入过列表中的点。不过这样做会给我们带来巨大的好处——可以避免重复多次检查同一个点。重申一遍,仔细地记录下已经检查过的点会给你带来巨大的好处。
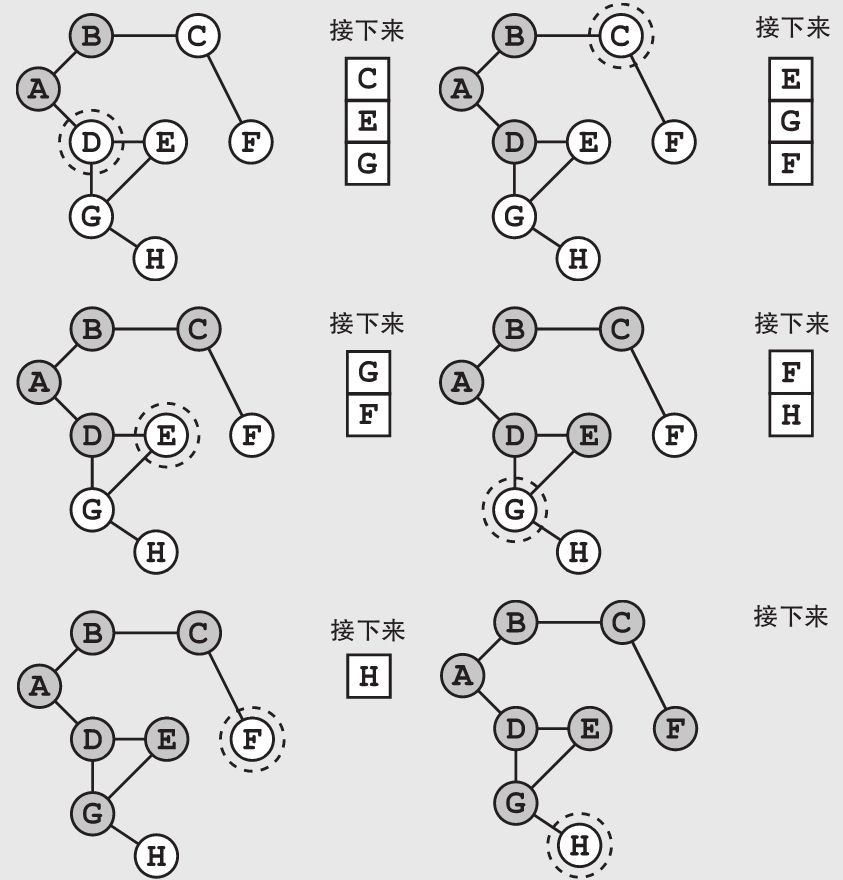
在这个具体的例子中,我们在H城市找到了要找的罪犯。至此我们可以在H城市逮捕他,结束搜索。
在搜索问题中,如果任意相邻的两个点之间移动的代价(例如所需的时间、体力,等等)是相等的,那么广度优先搜索可以保证找到一条花费最小代价的路径。这是因为它在检查完所有离起点距离X步的点后,才会开始检查那些更远的,例如离起点距离X+1步的点。
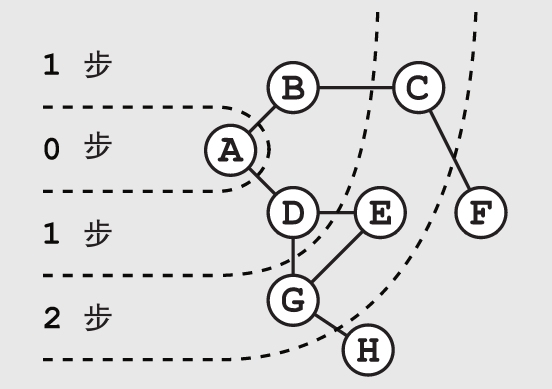
如果对于每个点都记下它是由哪一个点走来的,我们就可以很容易地追溯到这条最短路径。我们只要从终点开始,不断地回溯到它之前的一个点,直到回到起点就好了。
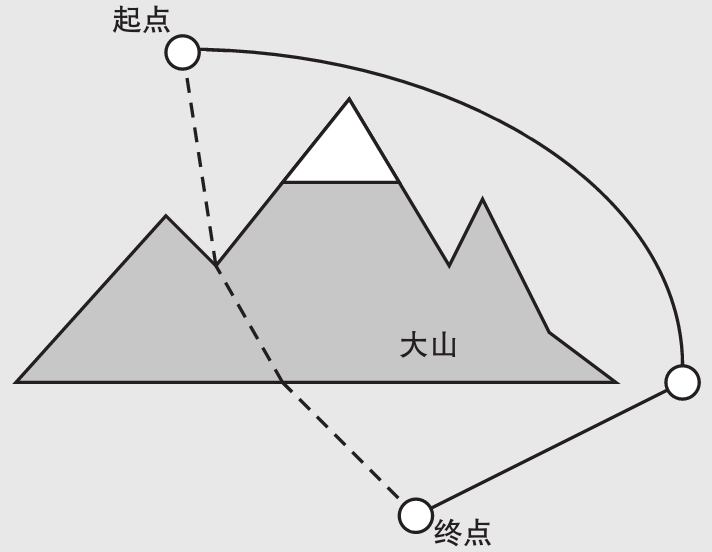
不过,值得注意的是,广度优先搜索只有在相邻点之间移动的代价都一样时才会给出最优的方案。一般来说,找出两点之间步数最少的路径和找出两点之间代价最小的路径是不一样的。举个例子,如果一群远足者想要尽量节省体力的话,他们宁愿会走一条相对较长但可以避开山路的路,即使穿山而过可能会使整个路程更短,也会更有观光价值,但走这段山路无疑会耗费更多的体力。