22 公文字典树(第2/2页)
警长说的没错。书柜中前缀为AS、CE、EX、NO、PR和RO的搁架里的文件全部被搬空了,而其他的却完好无损。他暗暗地记住了这些前缀,被偷走的这些前缀的文件中一定暗藏着什么信息。Frank有了另外一条线索。
他把手中的书放回到Dragon书柜的Registrations号搁架处,大声宣布:“好消息!档案记载首都只有几只食鸽龙,不过却有很多的鸽子。等我找到它时,至少那只可怜的龙不会被饿死。”
当Frank从档案室大步走出来的时候,John Cache怜悯地看了他一眼,什么也没有说。
警用算法导论:trie树
节选自Drecker教授讲义
trie树是基于树的数据结构,用户可以很方便地通过某个字符串的前缀来搜索到目标字符串。与二叉搜索树一样,trie树也是首先从根节点开始,然后一步步向下选取分支节点。在trie树中,每一个节点下的分支数(即有多少个子节点),取决于所有字符串中当前节点字母的下一个元素有多少种不同的可能。所以,trie树的每个节点可能不止两个子节点。
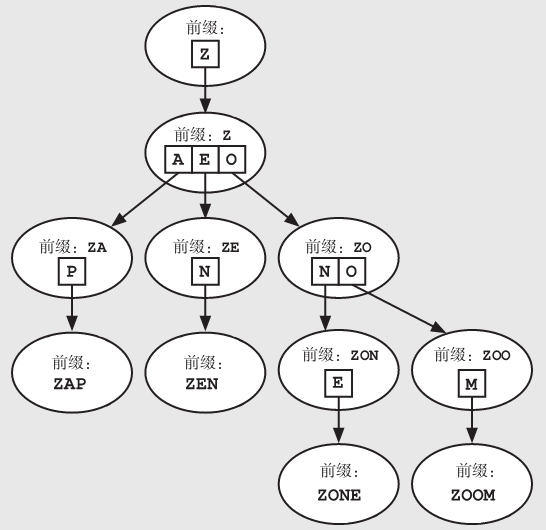
和二叉搜索树一样,我们只需将数据中出现过的节点依次插入到trie树中。例如,现在有单词ZAP、ZEN、ZONE和ZOOM。因为此时并没有ZONK这个单词,所以我们并不需要在ZON下面再设一个节点为K的子树。
注意,我们不需要在每个节点中存储一个字符串的所有可能的前缀,而是可以根据需要通过从树根到该节点的路径来重建出这个前缀。但是,有时也需要在每个节点中存储一些额外的信息,比如标记该节点是否为一个字符串或者单词的最后一个字母,以便我们区分当前插入的是一个单词还是一个单词的前缀。例如,我们无法确定树中的ZOO是否为一个独立的单词,因为还有一个单词是ZOOM。
trie树的搜索过程类似于二叉搜索树的搜索过程。算法从trie树的顶部开始向下进行。在每个节点,决定接下来应该选取哪个分支就需要看目标字符串的下一个字母是什么。例如,需要搜索ZEN这个字符串,搜索路径为:从Z开始,接着选择E这个分支,最后选择N这个分支。
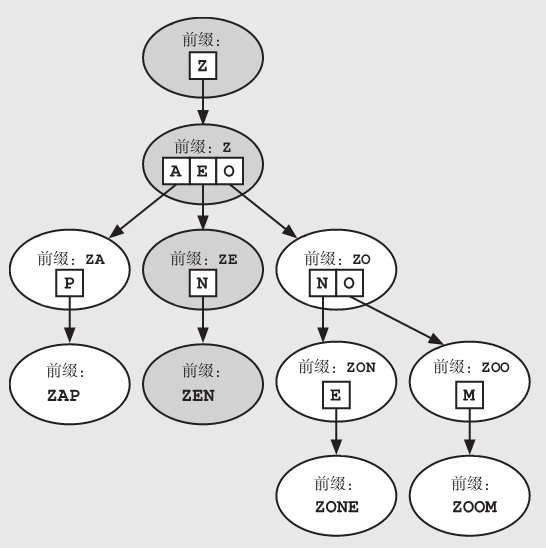
如果找不到这样的节点,就可以确定我们所需要的单词(字符串)不在树中。所以,如果我们在这棵树上搜索ZANY,我们会发现ZA之后便无路可走。
令人惊讶的是,警务中常常用trie树来编制犯罪嫌疑犯名单。举报者常常拒绝提供一个完整的名字,只会提供名字的前几个字母。此时,我们就可以使用trie树来对名字的前缀进行搜索,便可以得到与该前缀相匹配的所有人的名字。依据字母的数量和特殊性,这些信息足以大幅减少搜索范围。