13 用栈和队列搜索(第2/2页)
“你说过它们是用来做广度优先搜索的。”
“对,”Frank说道,“你之前用过的魔法列表就是一个队列。在广度优先搜索中,这个队列是用来记录还没有探索过的选择。不过每次是将和当前状态相邻的状态加到队列的尾部,而不是将当前状态推入栈中。”
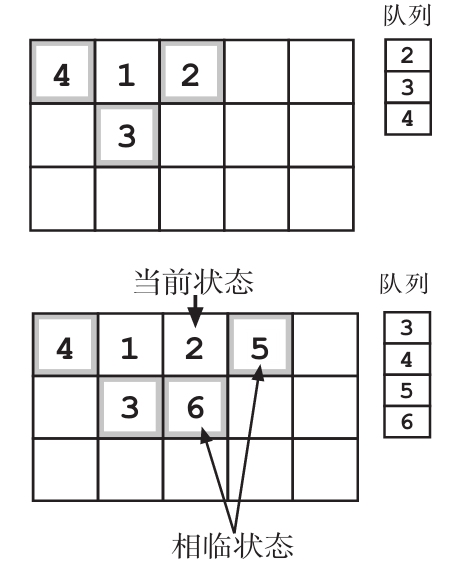
“那么在深度优先搜索的时候,你是用栈来记录没有探索过的状态,还是记录当前路径呢?”Socks问道。对于一个正从废弃监狱中逃离袭击者的人来说,他的语气听着出奇兴奋。
“只要你足够细心,两种方法都可以。”Frank说道。
“我从来没有从栈和队列的角度来想过搜索,”Socks沉思道,“肯定还有很多数据结构也被我忽视了。我打赌解绳之咒也用到了一些数据结构。”
Frank完全无视了Socks的自言自语,他们继续向出口走着。他们走得很快,不过是为了逃跑,而不是继续探索。Frank觉得袭击他们的人肯定已经走了,因为并没有人试图阻止他们逃跑。并且在烧掉证据之后,袭击者也并不需要继续留在这了。
过了几分钟,他们找到了出口,并冲了出去。他们身后溢出了一缕黑烟。到现在,大火应该已经把所有的纸都烧光了。他们所有的线索都被毁掉了。
警用算法导论:栈和队列Ⅱ
节选自Drecker教授讲义
信息是设计高效算法时不可或缺的要素。我们储存信息的方式和使用的数据结构,不仅会影响到算法的效率,也会决定算法的工作原理。从之前课上学到的深度优先搜索和广度优先搜索中,我们已经可以看出数据结构的重要性。虽然这两种搜索的算法在概念上是相似的,但我们用来储存状态的数据结构(栈或队列)不同,这在很大程度上决定了搜索会怎么进行下去。
选择数据结构时一定要小心,因为数据结构应该符合算法的需求。假设你选择使用图来存放一串排好序的数字,就算你能想方设法地来维护这列数字的顺序,也不能高效地进行二分搜索。这是因为图这种数据结构限制了我们存取数据的方式,我们不能像数组那样用下标序号来存取数字。这样一来,要想找到一个下标对应的数字,我们就必须进行一次线性查找,沿着图中的边逐个找下去。